
Les études menées à l'IRIT en Identification Automatique des Langues, ont pour but d’exploiter le maximum de sources. C’est pourquoi nous portons nos efforts sur la modélisation acoustico-phonétique, la modélisation phonotactique, la modélisation prosodique et la fusion de ces informations. Une première étude nous a conduit à proposer une approche différenciée au niveau acoustico-phonétique. Pour prendre en compte les paramètres structuraux des systèmes phonologiques, deux espaces, l’espace vocalique et l’espace consonantique, sont modélisés par deux modèles distincts pour chacune des langues. L’identification est obtenue par fusion adéquate des scores ainsi obtenus [Pel00] . Cette approche a montré une amélioration des résultats comparativement à une modélisation acoustique globale. Cette approche remet en cause la modélisation phonotactique. L'influence d'une telle séparation en classes phonétiques sur une modélisation phonotactique est étudiée. Ce premier travail se place dans un cadre idéal dans la mesure où nous utilisons en entrée de la modélisation un étiquetage manuel réalisé par des experts phonéticiens. Nous étudions les performances en reconnaissance de la langue d'un modèle phonotactique à base de multigrammes sur des classes de phonèmes. Nous présentons le modèle multigramme utilisé en section 2, le protocole expérimental en section 3 et nous discutons les résultats en section 4.
La modélisation par multigrammes consiste à trouver la segmentation S=(s1,… , sn(S)) la plus probable d'une séquence d'observations O=(o1,… , oT) :
avec la vraisemblance :
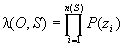
où Zi = (osi,… , os(i+1)-1)
L’algorithme d'apprentissage est un algorithme itératif de type EM. A chaque itération, sont estimées les probabilités a priori d'une séquence d'observations Zi :

avec
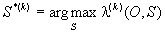
où >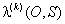 est la vraisemblance
de la séquence d'apprentissage O à l'itération
k, >
est la vraisemblance
de la séquence d'apprentissage O à l'itération
k, > est le nombre
d'occurrences de >
est le nombre
d'occurrences de >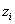 dans la
segmentation optimale >
dans la
segmentation optimale > .
La segmentation la plus probable >
.
La segmentation la plus probable > est estimée en utilisant un algorithme de Viterbi. Au cours de ces
itérations, les segmentations du corpus évoluent, faisant
émerger les séquences d'observation les plus typiques.
est estimée en utilisant un algorithme de Viterbi. Au cours de ces
itérations, les segmentations du corpus évoluent, faisant
émerger les séquences d'observation les plus typiques.
Après apprentissage, un dictionnaire est créé contenant les séquences Zi les plus probables et leur vraisemblance.
La phase de reconnaissance consiste à calculer la perplexité d'une séquence d'observation O en utilisant la segmentation la plus vraisemblable, suivant la formule :

où > est le nombre
d'observations de O et où la vraisemblance de cette même
suite est :
est le nombre
d'observations de O et où la vraisemblance de cette même
suite est :
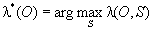
Le corpus est scindé en deux parties, l'une destinée à être utilisée pendant la phase d'apprentissage et l'autre pendant la phase de test. La partie destinée à l'apprentissage est constituée d'environ 70 locuteurs par langue, et celle destinée aux tests, 20 locuteurs. Les deux parties sont indépendantes, on ne retrouve pas de locuteur commun entre les deux sous corpus.
Les expériences consistent à faire varier à la
fois la longueur maximum autorisée des séquences du modèle
multigramme (de 3 à 5) et la composition des classes phonétiques.
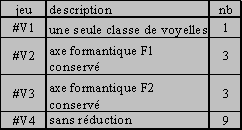
La variation des classes phonétiques consiste à réduire
le nombre de classes des consonnes en regroupant les classes voisées/non
voisées, en ne conservant qu'une classe pour les occlusives, en
regroupant les sonantes (tableau 1) et en ne considérant
qu'un seul des deux axes formantiques pour les voyelles (tableau
2).
 |
 |
Pour chaque langue, un modèle phonotactique multigramme est appris comme indiqué ci-dessus. Le problème d'identification consiste alors à trouver la langue qui maximise la probabilité d'observation de la séquence O :

ce qui revient à déterminer :

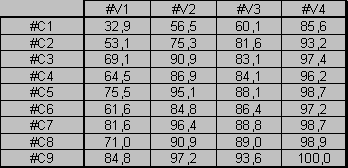 |
Globalement le fait d'autoriser une longueur maximum de 4 observations
pour une séquence au lieu de 3 améliore légèrement
les résultats (tableau 4).
 |
Par contre, en utilisant des 5-multigrammes, même si l'on conserve
des résultats proches des 4-multigrammes, les performances se dégradent
(tableau 5). La cause essentielle est certainement
liée à la taille insuffisante du corpus d'apprentissage pour
apprendre de tels modèles : les dictionnaires pour les 5-multigrammes
sont alors en moyenne constitués de 1600 séquences d'observations,
au lieu de 1000 pour les 3-multigrammes et 2000 pour les 4-multigrammes.
 |
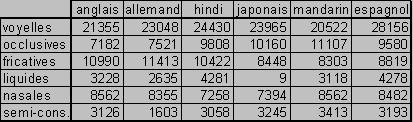
Afin d’interpréter plus justement ces résultats, il convient de préciser la répartition des grandes classes phonétiques parmi les langues (tableau 6) : elle est relativement homogène, les voyelles (avec environ 23000 occurrences sur le corpus d'apprentissage) représentent la plus grande partie des occurrences, deux fois plus que les occlusives et les fricatives (resp. 9200 et 9700). Notons cependant l’absence de liquides pour le japonais ; ce biais disparaît dès que les sonantes sont regroupées.
Si l'on compare les résultats obtenus pour les classes où l'on ne prend pas en compte le voisement (ensembles #C2, #C3, #C4, #C5) à ceux pour lesquels on distingue au sein d’une même classe de sons, les segments voisés et non voisés (resp. ensembles #C6, #C7, #C8, #C9), on constate une dégradation d'environ 10% des taux. En effet, certaines langues (hindi, mandarin et espagnol) privilégient des occlusives non voisées dans les séquences les plus probables, alors que d'autres (anglais, allemand) privilégient les occlusives voisées. A noter que le japonais met en avant des séquences d'occlusives avec un voisement mixte : un silence avant explosion non voisé avec une explosion et un relâchement voisé et vice versa.
Si l'on s'intéresse plus particulièrement à la réduction des consonnes liquides, nasales et semi-consonnes en une seule classe, les consonnes sonantes (ensembles #C2, #C3, #C6, #C7 par rapport à #C4, #C5, #C8, #C9), on ne note pas une dégradation des résultats de manière extrêmement sensible : nous ne perdons pas énormément d'information en regroupant ces trois classes phonétiques.
Si nous examinons les dictionnaires n-multigrammes (n=3,4,5) de chaque langue, le score relativement bas obtenu en utilisant une seule classe pour les consonnes et une seule classe pour les voyelles s'expliquent par le fait que les cohortes les plus fréquentes, à savoir CCC, CVC et VCC sont communes à toutes les langues. La cohorte CCC correspond généralement à l'enchaînement d'une fricative ou d'une sonante (C) et d'une occlusive (caractérisée par CC du fait de la distinction entre le silence avant explosion et l'explosion-friction).
Si nous examinons maintenant les séquences les plus fréquentes
dans le cas où nous avons le maximum de classes (9 voyelles et 9
consonnes), les séquences les plus fréquentes sont constituées
uniquement d'occlusives (anglais, hindi), ou d'occlusives suivi d'une voyelle
(allemand, japonais, espagnol), ou d'occlusives suivi d'une fricative (mandarin).
Les occlusives se retrouvent la plupart du temps dans les séquences
les plus fréquentes.
 |
[Haz97] T. J. Hazen, & V. W. Zue, (1997), "Segment-based automatic language identification", Journal of the Acoustical Society of America, Vol. 101, No. 4, pp. 2323-2331.
[Mat99] Matrouf D. et al (1999), "Comparing different model configuration for language identification using a phonotactic approach", Eurospeech'99, Budapest, Hongrie, pp 387-390. [pdf]
[Pel00] Pellegrino F. et al. (2000), "Identification automatique des langues par une modélisation diférenciée des systèmes vocaliques et consonantiques", Reconnaissances des Formes et Intelligence Artificielle, Paris.
[Del96] Deligne S. (1996), Modèles de séquence de longueur variables : application au traitemant du langage écrit et de la parole, Thèse de 3ème cycle, Ecole Nationale Supérieure des Télécommunications, Paris.
[Lan97] Lander T. (1997), The CSLU Labeling Guide, rapport interne, Center for Spoken Language Understanding, Oregon Graduate Institute. [ps.gz]
[Hie93]
Hieronymous J. L. (1993), Ascii phonetic symbols
for the world's languages: WorldBet. rapport interne, Bell Labs.
[ps.gz]