



Hazen
et
Zue
[Hazen et Zue 97]
ont
intégré
un
modčle
prosodique
ŕ
un
systčme
d'IAL
dans
un
cadre
probabiliste.
Le
systčme
est
constitué
d'un
modčle
acoustico-phonétique,
d'un
modčle
de
langage
phonétique
et
d'un
modčle
prosodique
(cf.
figure
4.1
pour
un
aperçu
du
systčme
global).
Etant
donné
le
vecteur
acoustique
![]() ,
la
vecteur
prosodique
,
la
vecteur
prosodique
![]() ,
la
séquence
phonétique
la
plus
probable
,
la
séquence
phonétique
la
plus
probable
![]() et
la
segmentation
associée
et
la
segmentation
associée
![]() ,
le
langage
le
plus
probable
,
le
langage
le
plus
probable
![]() est
trouvé
en
utilisant
l'expression
suivante :
est
trouvé
en
utilisant
l'expression
suivante :
![]()
ce qui revient ŕ écrire :
![]()
Les quatre probabilités de cette expression sont organisées de telle sorte que les informations phonétiques et prosodiques soient séparées. Ces termes désignent les différents modčles du systčme :
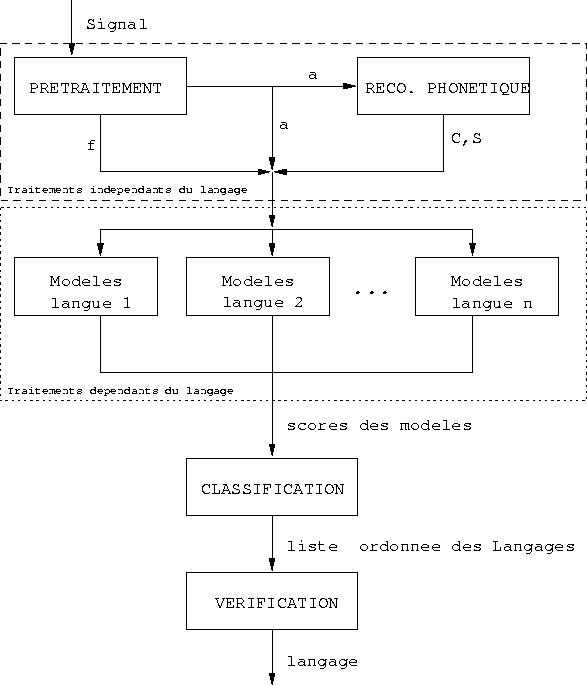
Figure 4.1: vue
globale
du
systčme
de
Hazen
et
Zue
Le
modčle
acoustique
est
utilisé
pour
capturer
des
informations
sur
les
phončmes
utilisés
par
chaque
langage.
Pour
simplifier
le
modčle,
Hazen
et
Zue
font
l'hypothčse
que
le
vecteur
acoustique
![]() est
indépendant
du
vecteur
prosodique
est
indépendant
du
vecteur
prosodique
![]() :
:
![]()
oů
![]() est
le
nombre
de
trames
dans
le
signal
et
est
le
nombre
de
trames
dans
le
signal
et
![]() est
le
vecteur
de
paramčtres
qui
décrit
l'acoustique
de
la
est
le
vecteur
de
paramčtres
qui
décrit
l'acoustique
de
la
![]() trame.
Le
vecteur
trame.
Le
vecteur
![]() est
constitué
de
14
MFCC
est
constitué
de
14
MFCC et
des
14
dérivées
associées.
et
des
14
dérivées
associées.
Le modčle phonétique de langage utilisé est un modčle trigramme interpolé, dont l'expression est :
![]()
oů
![]() et
et
![]() sont
les
poids
qui
dépendent
des
phončmes
précédant
sont
les
poids
qui
dépendent
des
phončmes
précédant
![]() .
.
![]() s'écrit :
s'écrit :
![]()
oů
![]() est
le
nombre
d'occurences
de
est
le
nombre
d'occurences
de
![]() dans
le
corpus
d'apprentissage
et
dans
le
corpus
d'apprentissage
et
![]() est
une
constante.
D'une
maničre
similaire
nous
avons :
est
une
constante.
D'une
maničre
similaire
nous
avons :
![]()
Le modčle prosodique se base sur des informations statistiques simples sur la fréquence fondamentale et la durée des segments. Pour simplifier le modčle, l'expression pour le modčle prosodique peut de développer comme suit :
![]()
Le
modčle
de
fréquence
fondamentale
![]() utilise
des
informations
du
contour
du
F0
d'un
signal.
Alors
qu'il
doit
y
avoir
une
corrélation
entre
le
contour
du
F0
et
le
durée
segmentale,
cette
corrélation
est
ignorée
pour
simplifier
le
modčle.
Donc
utilise
des
informations
du
contour
du
F0
d'un
signal.
Alors
qu'il
doit
y
avoir
une
corrélation
entre
le
contour
du
F0
et
le
durée
segmentale,
cette
corrélation
est
ignorée
pour
simplifier
le
modčle.
Donc
![]() est
considéré
comme
indépendante
de
est
considéré
comme
indépendante
de
![]() et
et
![]() .
Avec
ces
hypothčses,
le
modčle
de
fréquence
fondamentale
donne :
.
Avec
ces
hypothčses,
le
modčle
de
fréquence
fondamentale
donne :
![]()
Hazen et Zue considčrent maintenant que l'information qui est contenue dans la dynamique du contour du F0 est contenue dans les valeurs de la dérivée du F0 et qu'il n'est donc pas indispensable de modéliser spécifiquement cette dynamique. Pour simplifier le modčle, chaque trame est considérée comme statistiquement indépendante :
![]()
oů
![]() est
le
nombre
de
trames
dans
le
signal
et
est
le
nombre
de
trames
dans
le
signal
et
![]() est
un
vecteur
de
paramčtres
représentant
les
valeurs
du
F0
et
de
la
derivée
du
F0
pour
la
est
un
vecteur
de
paramčtres
représentant
les
valeurs
du
F0
et
de
la
derivée
du
F0
pour
la
![]() trame.
Il
faut
noter
que
le
calcul
de
cette
probabilité
n'est
effectué
que
sur
les
zones
voisées,
i.e.
que
sur
les
zones
oů
la
fréquence
fondamentale
est
définie.
L'expression
ci-dessus
a
été
modélisée
en
utilisant
un
mélange
de
Gaussiennes,
avec
9
fonctions
de
densité
estimées
avec
des
matrices
de
covariance
pleines.
trame.
Il
faut
noter
que
le
calcul
de
cette
probabilité
n'est
effectué
que
sur
les
zones
voisées,
i.e.
que
sur
les
zones
oů
la
fréquence
fondamentale
est
définie.
L'expression
ci-dessus
a
été
modélisée
en
utilisant
un
mélange
de
Gaussiennes,
avec
9
fonctions
de
densité
estimées
avec
des
matrices
de
covariance
pleines.
Le modčle de la durée segmentale ne tient pas compte des informations contenues dans l'accentuation des motifs des syllabes, des mots et des phrases du signal. En faisant l'hypothčse d'indépendance des segments, le modčle de durée s'écrit :
![]()
oů
![]() est
le
nombre
de
segments
dans
le
signal
et
est
le
nombre
de
segments
dans
le
signal
et
![]() la
durée
du
la
durée
du
![]() segment.
Cette
expression
est
modélisée
par
mélange
de
Gaussiennes.
segment.
Cette
expression
est
modélisée
par
mélange
de
Gaussiennes.
Les résultats ont été calculés ŕ la sortie du systčme global mais chaque modčle ŕ été évalué séparément, ce qui permet de mesurer l'importance relative de chaque composante. Sur le corpus OGI-MLTS, les résultats pour 11 langues avec des fichiers de parole spontanée de 10 et 45 s. sont les suivants :
| Modčles | 10 s. | 45 s. |
| Systčme complet | 65% | 78% |
| Modčle de langage | 62% | 77% |
| Modčle acoustique | 49% | 53% |
| Modčle de durée | 31% | 44% |
| Modčle de F0 | 12% | 20% |
Ces résultats sont compétitifs avec les autres systčmes d'IAL. Le modčle de langage est la modélisation la plus utile pour le systčme probabiliste, les informations des modčles acoustico-phonétique et prosodique pouvant tout de męme se révéler utiles pour améliorer les performances.