



Le but principal est de réaliser une modélisation des différentes unités (formes) prosodiques contenues dans le contour intonatif des zones voisées.

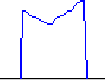
Figure 5.1: Contour
mélodique
d'un
signal
parlé
La première question qui est soulevée par une telle modélisation concerne le choix de l'unité temporelle. Une modélisation basée sur des trames n'est pas concevable, car elle ne reflète pas le caractère suprasegmental de la prosodie. En observant le contour intonatif d'un signal de parole (cf. figure 5.1 : la partie du haut représente l'évolution dans le temps de la valeur de F0, celle du bas le signal acoustique associé), il apparait qu'il existe déjà une segmentation au niveau du voisement : une zone voisée est caractérisée par un contour de la fréquence fondamentale non nulle, dont les valeurs du F0 sont comprises entre 50 et 200 Hz pour les hommes, et 100-400Hz pour les femmes ; une zone non voisée par un contour intonatif nul. La segmentation en unités prosodiques doit-elle être effectuée au niveau de la segmentation voisé/non voisée, ou utiliser un autre niveau, par exemple en choisissant des unités plus petites ? Un motif tel que :
doit-il être caractérisé par une seule unité prosodique (``creux'') ou plusieurs (une ``descente'' suivie d'une ``montée'') ? Il a été décidé d'essayer une modélisation dont les unités correspondent exactement à une zone voisée du signal dans le cadre d'une première approche.
10 formes élémentaires sont définies :
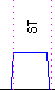 |
 |
 |
| stationnaire | bosse | creux |
|
|
|
|
 |
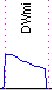
| montée légère | montée moyenne | montée forte | montée de fin de phrase |
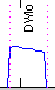 |
 |
 |
| descente légère (DWlo) | descente moyenne (DWmi) | descente forte (DWhi) |
Pour modéliser ces contours, une modélisation par Modèles Stochastiques de Trajectoires [Gong et Haton 94, Illina 97,] a été envisagée. Nous n'avons pas pu avoir accès à l'implémentation de ces modèles, et nous avons alors employé une modélisation par Modèles de Markov Cachés (MMC), qui permet de modéliser l'évolution temporelle des formes et qui se révèle intéressante du point de vue de la variabilité des formes.
Parmi les 10 formes considérées, 7 sont modélisées avec un seul état, et les 3 autres à l'aide de trois états (sans compter les états fictifs de début et de fin). Une seule gaussienne est utilisé pour décrire chaque état. Un seul état est utilisé pour modéliser une forme dont l'évolution dans le temps est monotone :
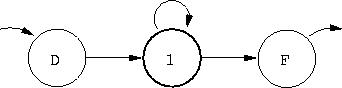
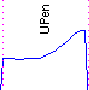
Les modèles à trois états sont assignés aux formes dont l'évolution dans le temps est plus complexe et qui nécessitent donc plus d'un état pour être représenté : il s'agit des formes UPen, TR, BU.

Il faut noter qu'avec une telle modélisation on perd les informations de durée des segments : en effet, un motif très étalé dans le temps et un autre motif du même type de durée plus courte sont modélisés par le même MMC. Ceci est dû au fait que les états bouclent sur eux-même, c'est-à-dire qu'à la sortie d'un état le réseau offre la possibilité de revenir dans cet état ou bien de changer d'état.
Il
faut
aussi
signaler
qu'un
nombre
minimum
de
vecteurs
de
paramètres
est
demandé
pour
entrer
dans
un
état.
Ainsi
avec
HTK ,
la
boîte
à
outils
utilisée
pour
réaliser
cette
modélisation,
il
est
nécessaire
de
disposer
d'au
moins
trois
vecteurs
prosodiques
pour
caractériser
un
état.
Ces
vecteurs
étant
calculés
toutes
les
10
ms.
(cf.
section
5.3)
les
formes
ne
seront
étiquetées
que
si
elles
sont
d'une
durée
supérieure
à
30
ms.
Ces
formes
sont
donc
étiquetées
``V''
pour
``zone
Voisée''.
,
la
boîte
à
outils
utilisée
pour
réaliser
cette
modélisation,
il
est
nécessaire
de
disposer
d'au
moins
trois
vecteurs
prosodiques
pour
caractériser
un
état.
Ces
vecteurs
étant
calculés
toutes
les
10
ms.
(cf.
section
5.3)
les
formes
ne
seront
étiquetées
que
si
elles
sont
d'une
durée
supérieure
à
30
ms.
Ces
formes
sont
donc
étiquetées
``V''
pour
``zone
Voisée''.
L'apprentissage est réalisé de manière empirique par succession d'essais et d'améliorations. Chaque modèle est initialisé par une douzaine de formes prosodiques étiquetées manuellement. Le corpus d'apprentissage est ensuite étiqueté par ce modèle. Lorsqu'une erreur d'étiquetage est décelée, la forme en question est rajoutée dans la liste des formes utilisée pour l'initialisation. L'étiquetage est alors relancé avec le nouveau modèle appris avec les nouvelles listes. Le processus est répété jusqu'à ce que l'étiquetage convienne. Les expérimentations n'ont jamais dépassé 10 cycles de modifications.
La phase de reconnaissance consiste d'une part à découper le signal en segments voisés distincts (à l'aide de la valeur de F0) et d'autre part à étiqueter chaque segment par le modèle prosodique (constitué des 10 MMC prosodiques). La figure 5.2 montre un exemple de segmentation et d'étiquetage.
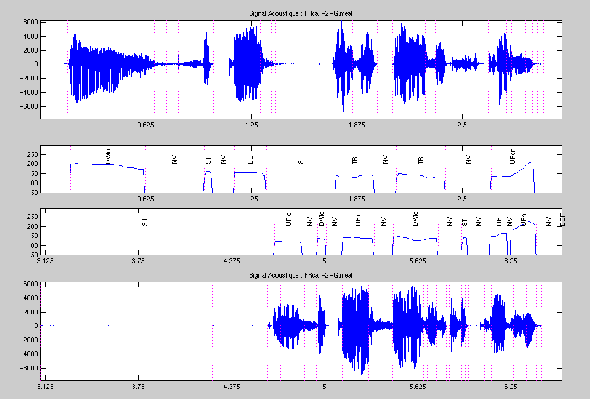
Figure 5.2: Exemple
de
segmentation
et
d'étiquetage